Project Objective
A city traffic department wants to collect traffic data using swarm UAVs (drones)from a number of locations in the city and use the data to improve traffic flow in the city, as well as a number of other undisclosed projects. Our task is to build a scalable data warehouse that will host the vehicle trajectory data extracted by analyzing footage taken by swarm drones and static roadside cameras. The data warehouse should take into account future needs, and organize data such that a number of downstream projects may query the data efficiently.
Project Tools
Apache Airflow - A workflow manager to schedule, orchestrate & monitor workflows. Directed acyclic graphs (DAG) are used by Airflow to control workflow orchestration. Postgresql - An object-relational database management system (ORDBMS) with an emphasis on extensibility and standards compliance. It is used as the primary data store or data warehouse for many webs, mobile, geospatial, and analytics applications. DBT (data build tool) - Enables transforming data in warehouses by simply writing select statements. It handles turning these select statements into tables and views. Redash - An open-source web application used for clearing databases and visualizing the results.
Given Data
The data we will be using for this project can be downloaded from pNEUMA data. pNEUMA is an open large-scale dataset of naturalistic trajectories from half a million vehicles in the congested downtown area of Athens, Greece. The one-of-a-kind experiment used a swarm of drones to collect the data. Each file for a single (area, date, time) is ~87MB of data.
Project Steps
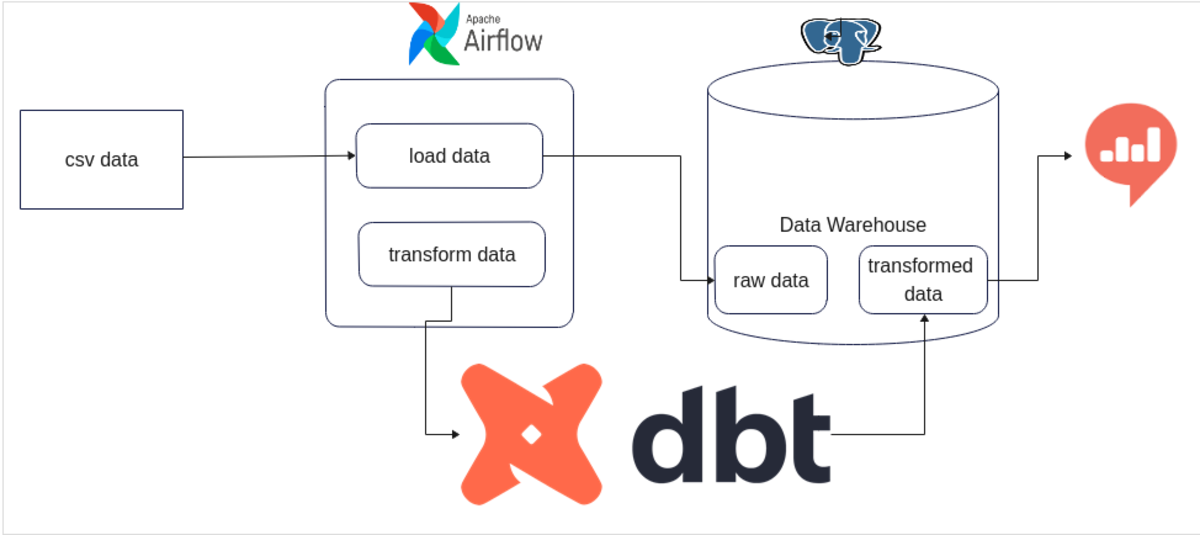
As you can see on the diagram, the project requires the following steps:
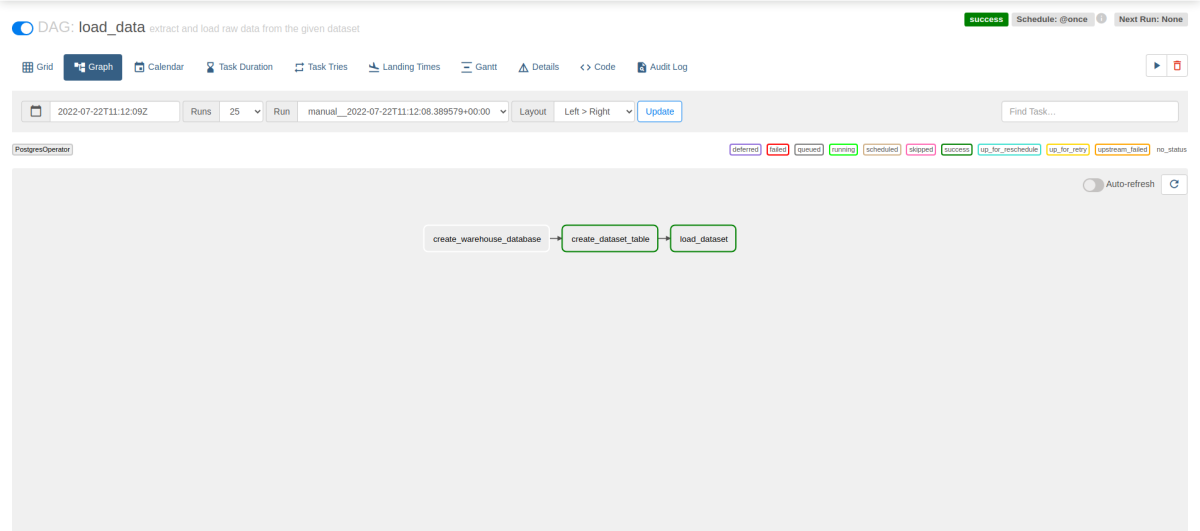
Data Loading and Airflow DAGS
The data we have has a column length of more than 121,000, which means inserting the data into the database would be hard, time-taking, and not efficient. For this reason, I compiled all columns after the time column into one separated by “_”, which would allow the loading of the data to be simple and efficient for now.
create_raw_data.sql
load_raw_data.sql
loader_dag.py
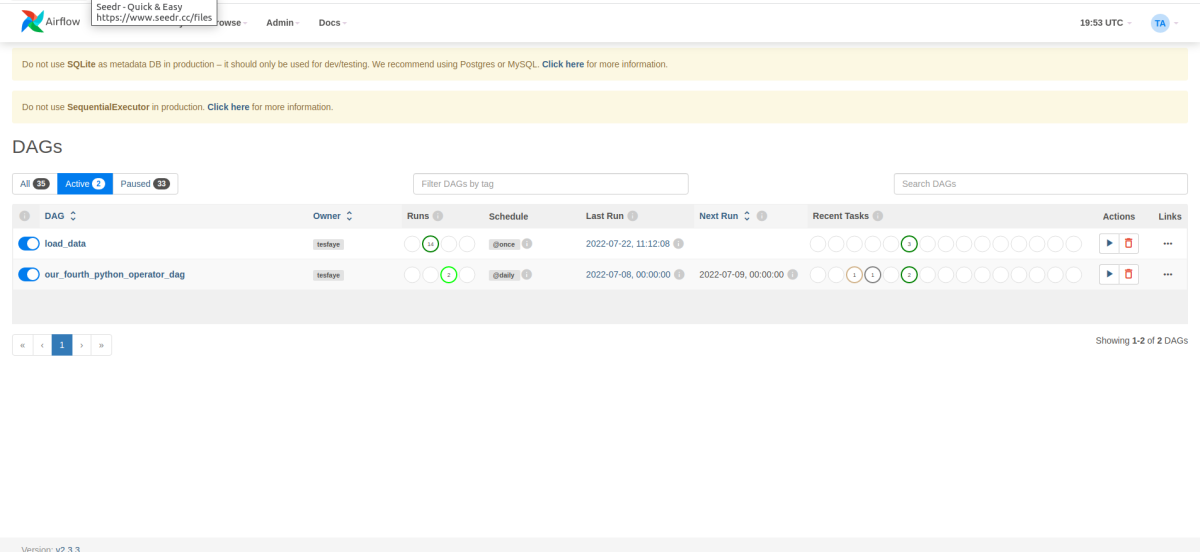
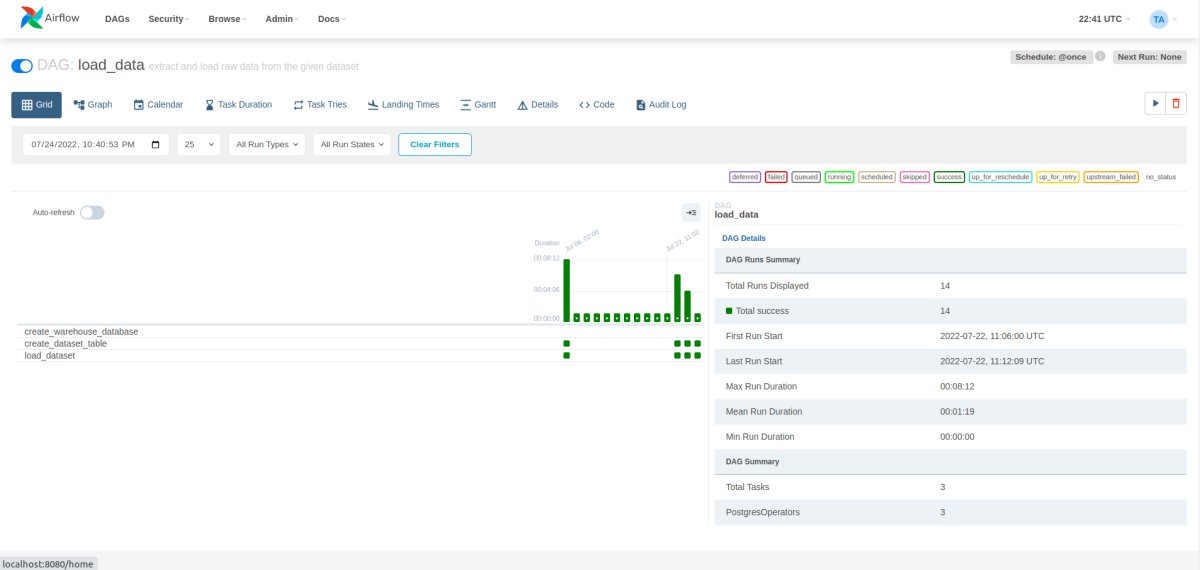
The above code enables to schedule table modification and create and load the SQL, which will give the following DABs on Airflow webserver.
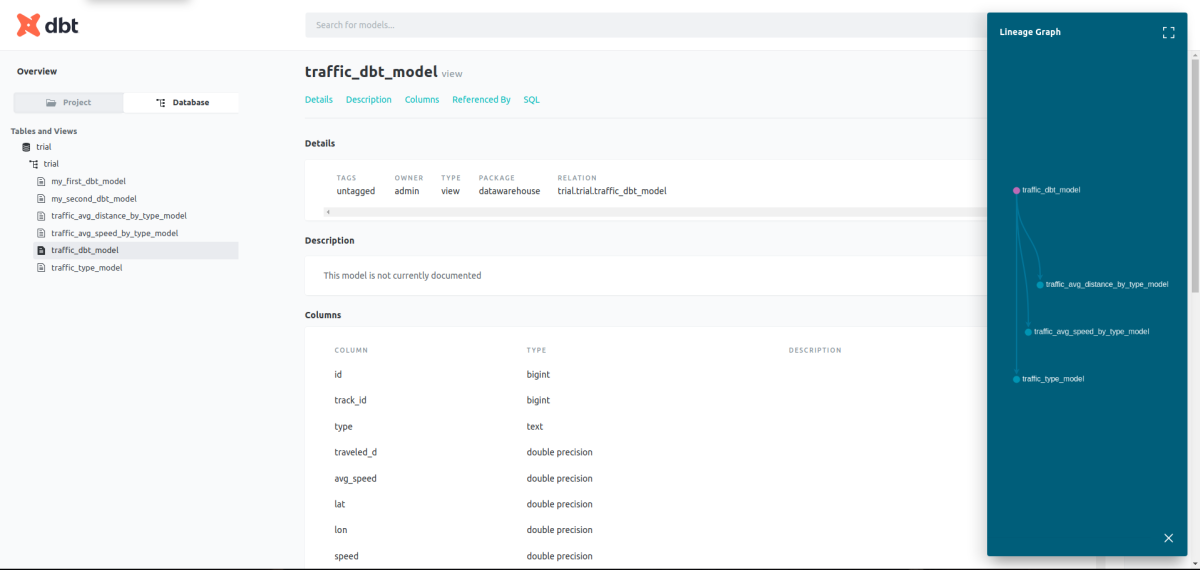
Writing DBT Model and Schema
After loading the data in Postgres, the next step to do is to transform the data to create other tables and views based on the main dataset.
Schema.yml
First DBT Model to Take Only the 10 Known Columns
DBT Model to Group by Type With Average Speed
Those DBT codes would create multiple views transforming the data. After this DBT would enable us to document our models and serve them locally.
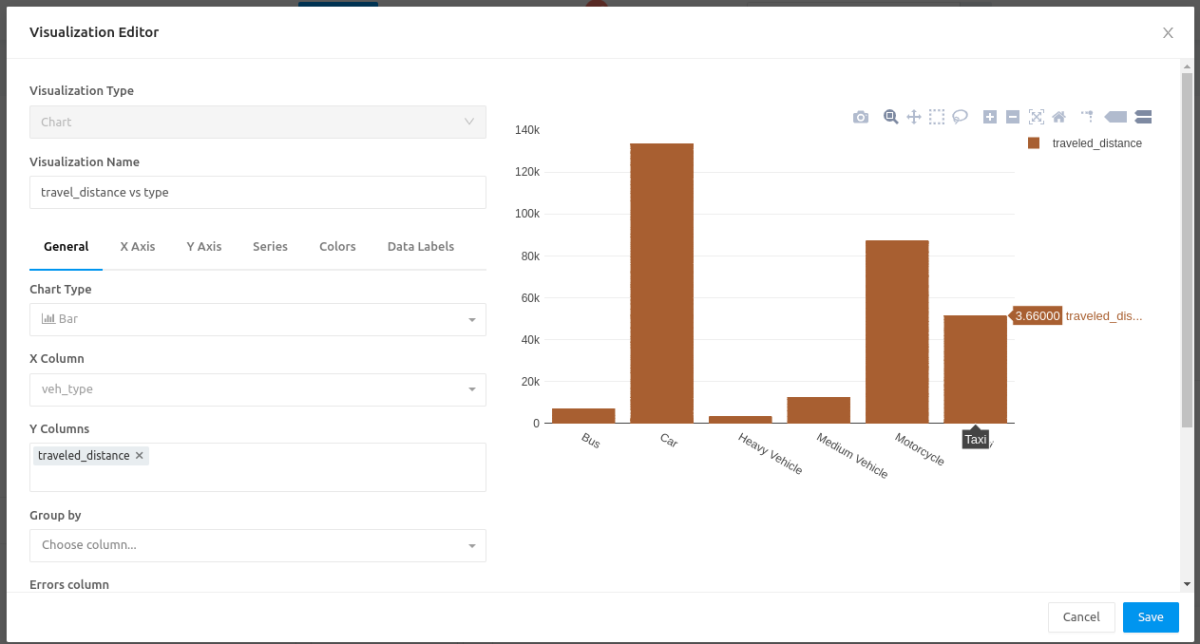
Creating a Dashboard With Redash
For this project, we can use Redash to create a dashboard and look at the views we made with DBT. Below is the Redash development environment as a sample.
Challenges Faced Implementing the Project
Challenges faced on this project include:
The data size and shape - were massive data and didn’t come as rectangular as needed. so that caused some problems but I was able to implement loading the data by modifying the raw_data Redash connection to localhost - as Redash is mostly installed using docker, it gave me a hardtime to connect to my localhost Postgres.
Future Plans and Conclusion
This project has been a good learning curve for me, but there are some tasks I wish to add to this project, which include:
Add more transformation on DBT to gain more insights. Build a more complete Redash dashboard.
Traffic Data Pipeline and WarehouseContribute to tesfayealex/traffic-data-pipeline-and-warehouse development by creating an account on GitHub.
This article is accurate and true to the best of the author’s knowledge. Content is for informational or entertainment purposes only and does not substitute for personal counsel or professional advice in business, financial, legal, or technical matters.